Self-service AI Tools

Self-service AI tools
Self-service AI tools enable rapid data processing and model development by replacing the coding parts of a data analysis task with a visual user interfaces by which users can interact with the underlying analysis settings. An effective self-service AI tool consists of different components for handling data access from a variety of sources, data wrangling and visualization, model as well as building AI models.
AI modeling components
The first steps in building a data-driven model is to import data from a data source. The data might be structured, residing in a relational database or unstructured requiring some preprocessing before being used for building models.
Data transformation, filtering, mapping, aggregation, running add hoc queries, statistical analysis of data, and data visualizations are typically performed to gain insight regarding the distribution and relationship between the different variables in a dataset.
The data may further undergo some preliminary analysis to select input features and potentially some data transformation to account for the issues stemming from significant difference between the range of variations for different features or the presence of highly correlated features that could adversely impact the performance of a data-driven model.
The transformed data are then used by machine learning (ML) algorithms to build data-driven models. The performance of the model is measured using a set of of quantitative measures which could guide the modelers for fine-tuning or modifying input features or ML model hyperparameters.
The final model is used to predict an outcome. For example a classification model trained on image data using an ML algorithm like random forest or an artificial neural network model can be used for predicting class labels associated to image pixels in an image segmentation problem.
Example
DataOrbs Inc. develops self-service analysis tools that streamline the different components of data-driven modeling including data import, data wrangling and visualization, AI model development and scenario analysis without writing a line of code. The developed models can be used as a scenario analysis tool or as a sub-model inside a Decision Support System (DSS).
Water Pump Status Prediction dashboard, developed by DataOrbs Inc. illustrates an example of a self-service AI dashboards that enables data exploration and visualization, feature selection, development of classification models, performance evaluation, and scenario analysis.
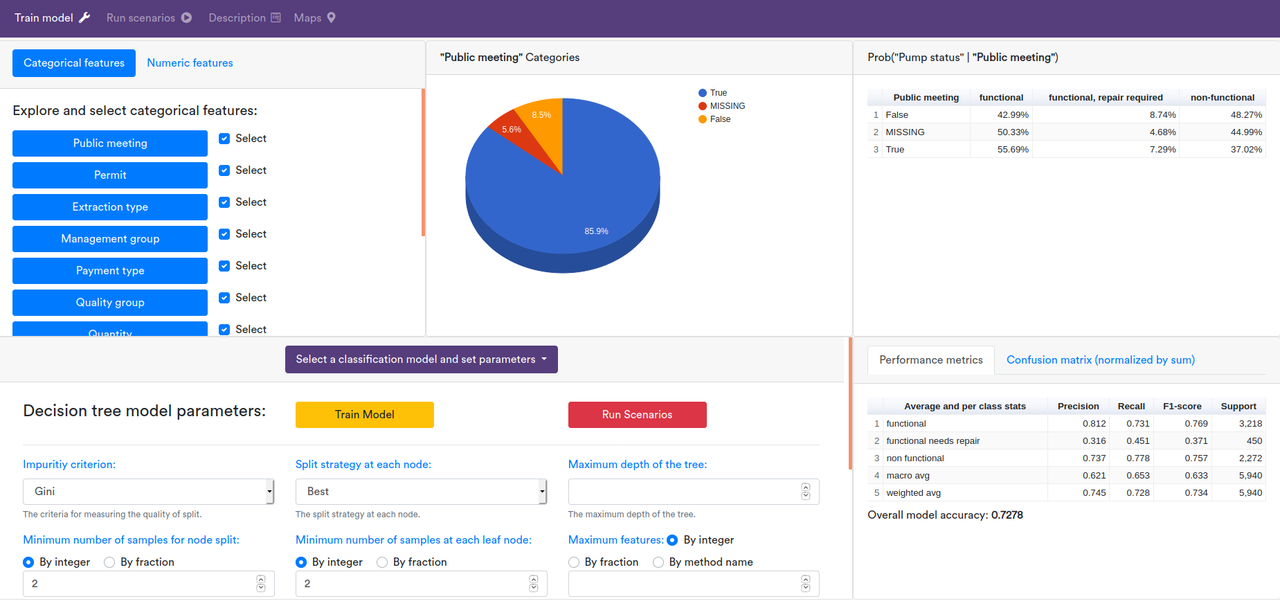
The dashboard enables users to build classification models using a set of numeric and categorical data types representing some management and physical characteristics corresponding to a number of water pumps (see data source). The feature data for building models can easily be selected through a set of check boxes. Users can access and modify model’s hyper parameters and model training settings through form components. A classification model can be trained and evaluated using a set of performance measures like Recall, Precision, F1-Score, and Confusion Matrix. If the trained model indicated a good performance the analysis can proceed with running scenarios.
